WM vorbei und beim Tippspiel wieder nichts abgeräumt? Willkommen im Boot! Ich auch nicht. Dabei dachte ich, dass ich das nötige Fußballwissen habe um gut tippen zu können. Doch hier regierte der Zufall, oder? Jedenfalls wollte ich wissen ob mein Fußballwissen ausgereicht hat um wenigstens besser als jemand zu sein, der einfach nur zufällig auf einen Sieger getippt hat (der Zufallstipper). Hier meine Analyse. Sie verrät euch wieviel Tippspiel-Punkte ihr haben müsstet um einigermaßen sicher sagen zu können, dass ihr besser wart als der Zufall. Nebenbei erklärt sie wie Wissenschaftler den Ausgang von Experimenten bewerten.
Dieser Post basiert auf einem IPython Notebook, welches ihr euch auch (hier) direkt anschauen könnt.
Jogi’s Jungs machten am Sonntag den WM-Titel klar und krönten damit eine aufregende WM mit dem Ereignis, das wir uns alle erhofft hatten. Doch mal ehrlich: Wer hat das denn vorher getippt? Ich jedenfalls nicht. Und leider lag ich auch bei den Tipps für die einzelnen Spiele zu oft daneben. So kam es, dass ich mal wieder am Ende unseres Tippspiels leer aus ging. Dabei hatte ich dieses Mal viele Spiele (zu viele, nach Meinung meiner Freundin) geschaut, Analysen gelesen und Quoten studiert um den nötigen Vorteil beim Tippen zu erarbeiten. Belohnt haben mich meine Tipps nicht. Bin ich zu doof zum Tippen? Wäre ich vielleicht besser gewesen, wenn ich einfach ohne nachdenken, zufällig getippt hätte? Um genau diese Frage zu beantworten, habe ich mir einen statistischen Test ausgedacht, der auf einem Tippsimulator basiert. Der nötige Programmcode befindet sich in folgender Datei, die ich nun lade:
In [1]:
run TippSimulator.py
Es folgen noch ein paar Erläuterungen zum Vorgehen. Dann, weiter unten, die Antwort.
Tippsimulator
In [2]:
worldcups = readWCHistory()
Die Spielstände der letzten zwei WMs füttere ich dann in meinen Tippsimulator:
In [3]:
sim = TippSimulator(worldcups)
Die Variable sim enthält nun einen TippSimulator, der Spielergebnisse tippen kann. Dabei aber typische Ergebnisse der letzten WMs berücksichtigt. Als Beispiel hier 7 zufällig getippte Spiele:
In [4]:
sim.generateScores(sim.stage1dist, 7)
Tippspiel
Um die Punkte fürs Tippspiel berechnen zu können, muss ich natürlich auch noch die Regeln des Tippspiels definieren. Diese habe ich in einer Klasse WC2104Tippspiel zusammen gefasst und dabei die Regeln unseres Tippspiels übernommen. Das waren die Standardregeln von kicktipp.de, das heißt, wir bekamen 4 Punkte für das richtige Ergebnis, 3 Punkte für die richtige Tordifferenz und 2 Punkte, wenn nur der richtige Sieger getippt wurde, oder wenn das Spiel unentschieden, aber mit einem anderen als dem getippten Unentschieden, ausging. Nach der Vorrunde tippten wir das Endergebnis nach möglichem Elfmeter.Natürlich braucht man auch die Spielergebnisse dieser WM um die Punkte für die Tipps berechnen zu können. All das wird von diesem Aufruf übernommen:
In [5]:
tip = WC2014Tippspiel()
Wieviel Punkte der Zufall bekommt
In [6]:
Pdist = tip.compPointDist(sim)
Das möchte ich natürlich mit meinen Punkten vergleichen. Dazu lade ich meine Tipps ins Programm und berechne die dafür erhaltenen Punkte vom Tippspiel. Gleichzeitig lade ich auch die Daten für den Gewinner unserer Tipprunde, der das Pseudonym “Noib” als Name gewählt hatte.
In [7]:
names, tscores = tip.readWC2014tipps()
tpoints = tip.compWCPoints(tscores)
tpointssum = tpoints.cumsum(0)
Nun kann ich alles zusammen in eine Abbildung bringen:
In [8]:
plotTippPointsWithDist(Pdist, tpointssum, names)
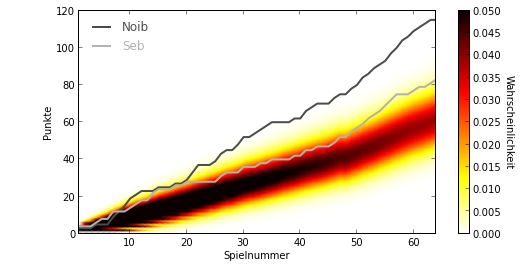
Die grauen Linien zeigen den Verlauf unseres Tippspiels für mich und Noib. Je mehr Spiele in der WM entschieden wurden, desto mehr Punkte haben wir natürlich gesammelt. Die Kurven steigen also nach rechts hin an. Anfangs hielt ich mit Noib noch gut mit, aber ab ca. Spiel 20 der WM war bei mir Punkteflaute und Noib setzte sich ab.Doch was macht der Zufallstipper? Ich habe seine Punkteverteilung farblich gekennzeichnet. Schwarz zeigt eine hohe Wahrscheinlichkeit für den jeweiligen Punktestand an und über rot und gold zu weiß sinkt die Wahrscheinlichkeit bis 0,0. Wahrscheinlichkeiten, die über 0,05 hinaus gehen sind auch mit schwarz gekennzeichnet. Man kann sehen, dass der Punktestand des Zufallstippers (natürlich) auch ansteigt. Dabei werden nach mehr Spielen immer mehr Punktestände wahrscheinlich, das heißt, für höhere Spielnummern sind mehr Punktestände farblich markiert.
Ein erstes Indiz dafür, ob ich besser war als der Zufall, ist ob sich mein Punktestand außerhalb des farbigen Bereichs befindet. Für die ersten paar Spiele sieht es so aus als hätte ich mich vom Zufall absetzen können, doch nach besagtem Spiel 20 habe ich mehrere Spiele hintereinander überhaupt keine Punkte bekommen. Da hat der Zufall dann wieder aufgeholt. Bis ca. zum Ende der Gruppenphase (Spiel 48) schwamm ich auf der Zufallswelle um dann von den leicht vorhersagbaren Spielergebnissen der Achtel- und Viertelfinals zu profitieren.
War ich wirklich besser als der Zufall?
Im Prinzip kann der Zufallstipper jeden beliebigen Punktestand erreichen. Die oben farbig gekennzeichneten Punktestände sind nur die, die der Zufallstipper am wahrscheinlichsten erreicht. Wie kann ich dann einigermaßen sicher sein, dass ich besser als der Zufallstipper war?Genau das gleiche Problem haben Wissenschaftler, wenn sie entscheiden müssen, ob ein beobachtetes Phänomen nur zufällig entstanden ist, oder tatäschlich von ihrer experimentellen Manipulation verursacht wurde. Zum Beispiel, könnte sich ein Arzt fragen, ob ein verabreichtes Medikament tatsächlich gewirkt hat. Dazu vergleicht er dann eine Kontrollgruppe, die nur ein Placebo bekommen hat mit einer anderen Gruppe, die das Medikament eingenommen hat. Die Kontrollgruppe ist hier der Zufallstipper, ich bin die Medikamentengruppe und wie stark die Beschwerden zurück gegangen sind ist der Punktestand. Der Arzt muss dann entscheiden, ob der Rückgang der Beschwerden in der Medikamentengruppe größer war als der in der Kontrollgruppe. Dazu schaut er sich an wie wahrscheinlich der Rückgang der Beschwerden in der Medikamentengruppe ist, wenn er die Variabilität des Rückgangs der Beschwerden in der Kontrollgruppe zu Grunde legt. Nur wenn der Rückgang der Beschwerden weit außerhalb des Bereiches liegt, der häufig in der Kontrollgruppe vorkommt, kann der Arzt sicher sein, dass das Medikament gewirkt hat und dass er den Rückgang der Beschwerden in der Medikamentengruppe nicht falsch dem Medikament zuschreibt (schließlich könnten die Beschwerden auch zufällig zurück gegangen sein). Genau dieses Prinzip wende ich nun auf mich und den Zufallstipper an.
Die Abbildung oben hat mir schon einen guten Eindruck davon vermittelt, dass ich zumindest zum Schluss des Tippspiels außerhalb des Punktebereiches lag, den der Zufallstipper häufiger erreichen würde. Das möchte ich nun auch noch anhand einer konkreten Zahl fest machen. Wenn der Zufallstipper viele Male mitgetippt hätte, würde diese Zahl ausdrücken in wieviel Prozent der wiederholten Tipps der Zufallstipper mehr Punkte bekommen hätte als ich. In der Wissenschaft nennt man das den p-Wert. Dort wird er allerdings eher als erwartete Fehlerwahrscheinlichkeit interpretiert: Wenn ein Experiment hypothetisch viele Male wiederholt werden würde, gäbe der p-Wert den Prozentsatz von Wiederholungen an, in denen der Wissenschaftler den falschen Schluss aus dem Experiment gezogen hätte. Im obigen Beispiel: Wie oft der Arzt den Rückgang der Beschwerden auf das Medikament zurück führen würde, obwohl tatsächlich nur der Zufall dafür sorgte.
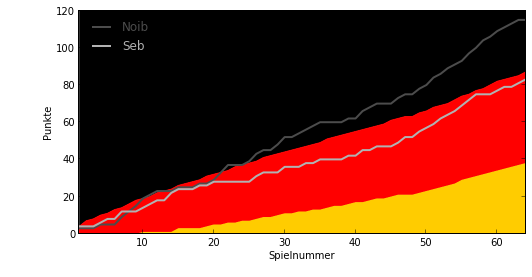
In der Psychologie reicht oft schon ein p-Wert von 5% (0,05) um als ‘signifikantes’ Ergebnis in einem Experiment anerkannt zu werden. Häufiger müssen p-Werte unter 1% liegen. In der folgenden Abbildung zeige ich daher die Punktebereiche, für die ich mit einem p-Wert von 0.01 sagen kann, dass ich besser (schwarz), oder schlechter (gold) als der Zufall war. Der rote Bereich markiert Punktestände, die man vom Zufallstipper erwarten kann (die Abbildung oben zeigt diesen Bereich im Detail).
In [9]:
plotTippPointsWithCDF(Pdist, tpointssum, names, pval=0.01)
Really interesting analysis. Enjoyed reading it.
It would be interesting to include all the previous worldcups instead of the last two. Maybe even look at the individual performances of the teams that participated in this edition throughout the worldcup history and include that in the prediction algorithm, to see if a very good predictor can be generated.
I do think thats too much work then 😀